Hackathon Licorne : le machine Learning & le développement de l’application
Ce projet, plus connu en interne sous le nom de « projet licorne » s’inscrit dans un projet plus large de Recherche et Développement de la Mobilery en lien avec les NIM (Nouvelles Interactions Mobiles) qui englobe notamment le Machine Learning, la Réalité Augmenté, le vocal, l’IOT…
C’est en février dernier que La Mobilery organisait son premier Hackathon en interne ! Dans un précédent article, nous vous avions présenté les objectifs et les avantages de ce processus en interne. Au-delà du fait de mettre en place un Hackathon, nous voulions aussi partager le travail qui a été conçu par nos équipes sur ces deux jours.
Pour ce premier Hackathon (appelé aussi projet Licorne) nous avons choisi les thèmes du Machine Learning et de la langue des signes. Notre équipe s’est donc lancée dans la création d’une application de traduction en temps réel de la langue des signes en entrainant un modèle de machine Learning à la reconnaissance des lettres. Ce projet a été structuré autour de trois axes : le modèle du réseau neuronal, le développement de l’application et l’expérience utilisateur.
Les participants de ce Hackathon n’étant pas forcément des spécialistes en Intelligence Artificielle et Machine Learning, l’objectif n’était pas de faire un modèle viable en 2 jours, mais bien d’approfondir les connaissances dans le Machine Learning afin de mieux en comprendre les enjeux et de pouvoir collaborer par la suite avec les Data scientists.
#1. Le modèle du réseau neuronal
Le fonctionnement d’un réseau neuronal
![]()
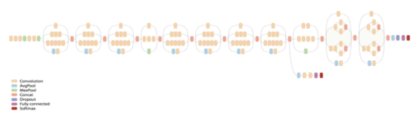
Le principe d’un modèle de réseau neuronal est de constituer un réseau capable d’analyser des images (dans notre cas) pour en déduire une probabilité de présence dans l’image d’une forme définie.
Ce réseau se compose de plusieurs couches de neurones, qui ont toutes une fonction bien définie, et donc une forme de traitement spécifique. Chaque couche analyse l’image successivement, puis remonte les informations de son analyse à la couche suivante. La dernière couche fusionne l’ensemble des informations afin de déterminer la probabilité globale de présence de la forme recherchée dans l’image.
Afin de faciliter (relativement) le travail, nous avons utilisé la bibliothèque de fonction de manipulation du réseau neuronal TensorFlow, fournie par Google. Plutôt que de partir d’un réseau vierge, nous avons choisi des réseaux préexistants, Inception V3 et MobileNET, afin de n’avoir à générer que la dernière couche d’analyse neuronale.
Apprentissage & auto-test

Pour que ce réseau neuronal fonctionne, il est nécessaire de lui apprendre à reconnaître la forme adéquate. Cet apprentissage se fait en utilisant un ensemble d’images variées représentant la forme que l’on souhaite lui apprendre. Chaque couche du réseau analyse les images une à une, et adapte son comportement à chaque nouvelle image, pour affiner son analyse. La bibliothèque TensorFlow permet de n’utiliser qu’un pourcentage des images, pour que le réseau s’auto-test au fur et à mesure de son apprentissage. Dans ce processus, la qualité, la quantité et la diversité des images fournies lors de la phase d’apprentissage joues un rôle majeur sur la qualité de la restitution de l’analyse.
Les informations (réglages) que l’on indique au réseau pour chaque image sont également très importantes, afin d’entrainer le modèle à s’adapter aux différentes conditions d’analyse. Pour entraîner notre modèle, nous avons utilisé un lot de 90.000 images de chaque lettre de l’alphabet des signes américains. Après plusieurs essais et différents changements de réglages, nous avons obtenu un résultat satisfaisant sur l’apprentissage et les tests automatiques. En fonction des réglages, la phase d’apprentissage a pris de 1h à 5h (voir plus) de temps de calcul sur nos machines de développement. Les tests en conditions réelles, basés sur des photos prises à la volée, et sur des captures webcam, bien que déjà très satisfaisants, n’ont pour autant pas toujours donné tous les résultats escomptés.
Le timing court des 2 jours d’Hackaton n’ont pas permis l’analyse détaillée des résultats via TensorBoard par les spécialistes, cette phase sera à envisager post Hackaton. Une autre piste que l’équipe envisage aussi post Hackaton pour optimiser ces traitements, sera d’enchainer plusieurs réseaux neuronaux : un pour la détection de la main, et un second pour la reconnaissance du signe, … A suivre donc !
#2. Le développement de l’app
Pour concrétiser notre projet, nous avons réalisé une application iOS écrite en Swift. Cette app intègre le modèle entrainé au format CoreML, ainsi que des représentations des signes (images fixes et vidéos). Le principe de l’application repose sur la capture de flux vidéo en temps réel via Vision. Il intercepte, à intervalle de temps régulier (une seconde), une image. Cette image sera ensuite transmise au modèle pour l’analyse, par le biais de l’API CoreML.
Les différents résultats de cette analyse sont comparés pour en extraire la réponse la plus pertinente, qui sont ensuite retranscrits sur l’interface de l’application. L’application embarque également une base de données locale issue d’un fichier JSON, utiles aux autres fonctionnalités que nous avons imaginées pour notre projet.
L’application n’étant pas en ligne, n’hésitez pas à nous contacter pour une petite démo live, ou pour tout simplement échanger sur celle-ci ! 😉
Enfin, pour en savoir plus sur le troisième axe de ce projet : l’expérience utilisateur de cette application c’est par ici 🙂
Vous pourriez également aimer…


Communiqué de Presse : La Mobilery et Leviatan annoncent leur rapprochement stratégique
La Mobilery et Leviatan, deux entreprises françaises dans le domaine des nouvelles technologies, annoncent aujourd’hui leur rapprochement stratégique, formant ainsi le groupe LMLT, un nouveau groupe fort d’une centaine de collaborateurs, et ayant une présence géographique dans les Hauts-de-France, Paris, Centre Val de Loire et en Auvergne Rhône-Alpes.

