UX Days 2019 : UX + DATA = ♥
Emmanuelle MARÉVÉRY, Consultante – Directrice UX & Innovation
Le point de départ : nos biais cognitifs et de raisonnements, notre manque d’informations, nous font produire des suppositions souvent fausses, ou au moins inexactes, sur le monde, et sur les utilisateurs que nous devons tenter de comprendre le mieux possible. D’autre part, “la data” est omniprésente, comme le dit Emmanuelle Marévéry, “chacun de nous génère des données dès lors qu’il réalise une action sur un site ou une application, qu’il utilise un objet connecté ou simplement quand il se déplace avec son smartphone. Chaque jour, c’est ainsi plus de 2,5 trillions d’octets de données qui sont créés”.
C’est autant d’informations qui seront susceptibles d’aider les professionnels de l’UX, entre autres, à mieux comprendre les utilisateurs, que ce soit qualitativement ou quantitativement.
L’enjeux derrière la data, est donc de prédire plus efficacement les comportements des utilisateurs. Pourtant, aujourd’hui, la data n’est pas utilisée à son juste potentiel dans les entreprises.

Une des raisons de cette sous-utilisation, c’est probablement la difficulté de la procédure, de la définition du cadre de l’analyse à mener, jusqu’à l’action concrète à mener dans le projet.
C’est en effet un métier à part entière, celui de Data Scientist, qui se retrouve régulièrement dans les top des métiers les plus satisfaisants (élu meilleur métier des États-Unis, 4 années consécutives, de 2016 à 2019, sur le classement Glassdoor).
Vers une démarche plus scientifique
Sans pousser si loin dans la technique, plusieurs outils et techniques permettent aux moins avertis d’entre nous de faire parler la donnée. Par exemple, une nuage de mots permet de voir, en un seul coup d’oeil, les mots-clefs qui accompagnent un sujet.

Il est aussi possible de recueillir des commentaires, avis, et le nombre de vues sur des vidéos Youtube par exemple, ou sur des sites d’associations de consommateurs, etc. Il est aussi relativement facile de récupérer une quantité importante de données en demandant directement à un panel d’utilisateurs sur les réseaux sociaux de répondre à des questionnaires sous forme de complétion de phrases par exemple (voir la conférence de Emeline Mercier des UX DAYS 2017 “ »Comment j’ai collecté 14.000 insights utilisateurs en 15 jours »). Pour traiter des données d’autres types, plus nombreuses, et aller plus loin, on pourra alors utiliser des logiciels spécialisés comme R (logiciel libre, et langage, classé 12e dans l’index TIOBE qui mesure la popularité des langages de programmation, en janvier 2019).
Emmanuelle Marévéry citant Euclide, nous rappelle que “ce qui est affirmé sans preuves peut être réfuté sans preuves”. Or, la donnée vient répondre à des hypothèses posées à priori, pour les confirmer ou infirmer. Rentrer la data dans notre processus de travail, c’est donc se rapprocher de la démarche scientifique.
Cette présentation est une invitation forte à réaliser des études hybrides, ou mixtes, qui mêlent les données qualitatives aussi bien que quantitatives.
Que faire avec des mots ?
La dernière partie de la conférence est consacrée au “text-mining” ou “la fouille de texte”. Le texte est une donnée bien spécifique, particulièrement difficile à manipuler. Pourtant elle est extrêmement utile. Trouver les bons mots, pour nommer les produits, les hashtags appropriés, classifier des produits ou services, améliorer l’expérience utilisateur, ou faire de la recherche utilisateur indirecte, ne sont que quelques exemples que donne Emmanuelle Marévéry de l’utilité de la fouille de texte. La recrudescence de l’intelligence artificielle, qui est toujours extrêmement loin de ressembler à de l’intelligence humaine, est aussi un domaine de choix pour les méthodes de fouilles de textes.
Concrètement, comment on s’y prend avec le texte ?
Il y a plusieurs manières de faire parler les données textuelles, par exemple:
- Occurrences: c’est compter le nombre de fois qu’un mot apparaît. L’idée ici est que plus il apparaît, plus il est important pour le sujet du document pour lequel vous avez compté les mots
- Fréquences: c’est compter le nombre de fois qu’un mot apparaît, par rapport à un nombre de documents. Par exemple, le mot “Harry” apparaît un nombre X de fois dans les 7 tomes de la série des livres de JK. Rowling; La fréquence du mot “Harry” est donc de X / 7
- Fréquences inverses (TF-IDF, pour Term Frequency-Inverse Document Frequency): Il s’agit de compter l’inverse de la fréquence d’un mot dans plusieurs documents. Si on reprend l’exemple de Harry Potter:
- le mot “Hagrid” est présent X fois, dans les 7 tomes, sa fréquence est donc X / 7; Hagrid est un personnage secondaire, présent tout au long de l’aventure, donc dans les 7 tomes.
- le mot “dragon” est très occurrent dans le livre 4, puisque Harry se bat contre un dragon, mais très peu dans les autres. La fréquence de “dragon” est alors très hétérogène. Autrement dit, le mot “dragon” étant très spécifique au livre 4, il est un bon discriminant de ce livre, tandis que le mot “Hagrid”, a une fréquence plus élevée globalement, mais ne discrimine pas les livres entre eux.
- Le TF-IDF est très utile pour donner un poid important aux mots qui apparaissent dans peu de documents, car ils sont plus discriminants
- Co-occurrences: on ne cherche pas un terme seul, mais les mots qui sont les plus fréquents ensembles. Si on suit notre exemple, la plus forte co-occurrence avec “Professeur” pourrait être “McGonagall”.
- Corrélations: à quel point chaque mot apparaît en même temps qu’un autre mot ? Par exemple, les mots “dragon” et “norbert” ont une corrélation élevée, tandis que les mots “Dursley” et “Baguette” ont une corrélation très faible.
- Analyse de sentiments: il est possible, en s’aidant de lexiques de mots catégorisés, de trouver la valence, positive (ex: “bonheur”, “joie”) ou négative (“triste”, “mal”), des mots de notre corpus de textes.
- Classifications : Il s’agit d’utiliser un algorithme qui va catégoriser les mots qui vont ensemble, sur une base de critères donnés. Une fois l’analyse effectué, on peut visualiser le résultat par des dendrogrammes, ou des analyses factorielles des correspondances
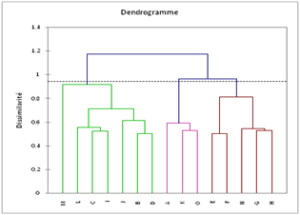

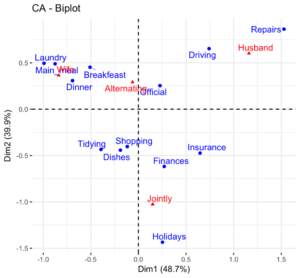
Retrouvez l’intégralité des articles écrits durant les UX DAYS de 2019 ici !
Vous pourriez également aimer…


Communiqué de Presse : La Mobilery et Leviatan annoncent leur rapprochement stratégique
La Mobilery et Leviatan, deux entreprises françaises dans le domaine des nouvelles technologies, annoncent aujourd’hui leur rapprochement stratégique, formant ainsi le groupe LMLT, un nouveau groupe fort d’une centaine de collaborateurs, et ayant une présence géographique dans les Hauts-de-France, Paris, Centre Val de Loire et en Auvergne Rhône-Alpes.

